
2026年3月25日、xAI公式アカウント @grok が突如このポストをしました。
“Grok Imagine multi-image to video and video extension are now available on API. Use up to 7 images to create a video or extend existing videos by 10 seconds.”
最大7枚の画像を参照して動画を生成できる「マルチ画像対応」、そして既存の動画に続きを生成できる「動画延長」——どちらも待望の機能です。
ただ、いざ使ってみると「画像を参照するってどうやるの?」「エンドフレームって指定できるようになったの?」「動画延長したらゴーストみたいなものが映り込んだんだけど……」という疑問がすぐに出てきます。そこで本記事では、公式ドキュメントと実際の使用体験をもとに、これらの疑問に一つひとつ答えていきます。
目次
- Grok Imagineとは何か、何ができるのか
- 2026年3月アップデートの全容
- 画像to動画(i2v)の基本
- リファレンス画像でキャラクターを参照する
- Web版での画像参照の実際——記法の疑問に答える
- リファレンス画像が思い通りにならない理由と対策
- エンドフレームは指定できる?現状と代替手段
- 思い通りの動画を作るための実践テクニック集
- 動画延長機能の使い方
- ゴーストアーティファクト問題——何が起きているのか
- プラン比較:LiteとSuperGrokどちらが必要か
- まとめ
Grok Imagineとは何か、何ができるのか
Grok Imagineは、xAI(イーロン・マスク率いるAI企業)が提供する画像・動画生成サービスです。ブラウザから grok.com/imagine にアクセスするだけで使えるWeb版と、開発者向けのAPIの両方が提供されています。
本記事では主にWeb版(grok.com/imagine)での使い方を中心に解説します。APIを使う方向けの情報は補足として記載します。
Grok Imagineで使える5つのモード
Grok Imagineには現在、以下の5つの生成モードがあります。
| モード | 概要 | 入力 |
|---|---|---|
| テキスト→画像(t2i) | プロンプトから静止画を生成 | テキスト |
| テキスト→動画(t2v) | プロンプトから動画を生成 | テキスト |
| 画像→動画(i2v) | 1枚の画像を最初のフレームとして動画を生成 | 画像+テキスト |
| リファレンス画像→動画 | 最大7枚の参照画像を使って動画を生成 | 複数画像+テキスト |
| 動画延長 | 既存の動画に続きを追加生成 | 動画+テキスト |
「i2vとリファレンス画像って同じじゃないの?」と思う方も多いですが、この2つはまったく別の機能です。この違いが、後で解説するキャラクター参照やエンドフレームの話の核心になります。
AI動画生成の中での位置づけ
Grok Imagineのモデル(grok-imagine-video)は、AI動画生成の第三者評価機関・Artificial Analysisのリーダーボードにおいて、**2026年3月時点で総合6位(Eloスコア1,229)**を記録しています。2026年1月末には1位だったこのモデルは、競合の急成長もあり順位を下げましたが、コスト($4.20/分)とのバランス感では引き続き有力な選択肢のひとつです。(出典:Artificial Analysis Text-to-Video Rankings、2026年3月31日調査)
2026年3月アップデートの全容
2026年3月25日のアップデートで追加されたのは大きく2つです。
@grok(2026年3月25日):「Grok Imagine multi-image to video and video extension are now available on API. Use up to 7 images to create a video or extend existing videos by 10 seconds. Try it here: x.ai/api/imagine」
追加された機能
① リファレンス画像(複数画像対応)
これまでt2v・i2vのみだったところに、複数の画像を「参照素材」として動画生成に使えるリファレンス画像機能が加わりました。最大7枚を指定でき、キャラクターの顔・衣装・小道具などを別画像で渡して動画に反映させることができます。
② 動画延長(Video Extension)
生成済みの動画の末尾から続きを生成し、1本の動画として出力できる機能です。最大10秒の延長が可能で、延長後の動画は元の動画と結合された状態で返ってきます。
また同週の3月28日、公式アカウント @imagine は、クリエイターによる作例動画をシェアしながらこう呼びかけています。
“Put on your film director hat and show us your stories. There’s never been an easier time to get creative.”
画像to動画(i2v)の基本
リファレンス画像との違いを理解するために、まず通常の「画像→動画(i2v)」の仕組みを整理しておきます。
i2vとは
i2vは、アップロードした1枚の画像が**動画の最初のフレーム(スタートフレーム)**になる機能です。AIはその画像から続くシーンをプロンプトの指示にしたがって生成します。
Web版でのi2vの使い方
- grok.com/imagine にアクセスし、ログイン
- 入力欄の「画像」ボタンから画像を1枚アップロード
- 出力形式を「動画」に切り替える
- プロンプトに動かし方の指示を書いて生成
i2vで得られる動画の性質
- アップロードした画像がそのまま最初のコマになるため、スタート状態は正確にコントロールできる
- その後の動きはプロンプト次第で、AIが補完する
- 入力画像のアスペクト比が出力動画にデフォルトで引き継がれる
- 最大15秒まで生成可能
i2vに向いているシーン・向いていないシーン
向いている:特定の背景・キャラクター・ポーズから「ここから動かしたい」と決まっているとき。ゲームのスクリーンショットをアニメ化したい、イラストに動きをつけたい、など。
向いていない:複数のキャラクターを登場させたいとき、スタートとエンドの両方を指定したいとき(後述)。これらはリファレンス画像や延長との組み合わせが必要です。
リファレンス画像でキャラクターを参照する
リファレンス画像機能は、i2vとは根本的に異なるアプローチです。
i2vとリファレンス画像の本質的な違い
| i2v | リファレンス画像 | |
|---|---|---|
| 入力画像の役割 | そのまま最初のフレームになる | 参照素材。参照方法によって挙動が変わる(後述) |
| キャラクターの一貫性 | 最初のフレームの見た目が引き継がれる傾向あり | プロンプトで明示的に指定した要素が反映される |
| 複数画像 | 1枚のみ | 最大7枚 |
| 最大尺 | 15秒 | 10秒 |
| 使い所 | 特定の静止画を動かす | キャラ・衣装・小道具を組み合わせる |
重要な点:リファレンス画像は「この画像のキャラクターをそのまま動かす」のではなく、「この画像を参考にしてキャラクターが登場する動画を作る」という機能です。ただし、プロンプト内での参照枚数・参照回数によって挙動が変わります(後述)。参照画像に完全一致するとも限りません。
参照枚数で挙動が変わる——i2vモードとリファレンスモードの境界
r/grokコミュニティの検証によると、プロンプト内での参照の仕方によってリファレンス画像の挙動が大きく変わります。(出典:Spra991氏の投稿、r/grok、2026年3月)
- 1枚の画像を1回だけ参照する → 通常のi2vと同じ挙動になります。その画像が動画の最初のフレームとなり、そこからプロンプトの動きに移行します
- 複数の画像を参照する(2枚以上、または同じ画像を2回) → 真のリファレンスモードになります。画像がスタートフレームに固定されず、プロンプトで指定したシーンからそのキャラクターで始められます
1枚の画像しかない場合でもリファレンスモードで使いたいときは、同じ画像を2回参照するワークアラウンドが有効です。
@Image 1 @Image 1 is running through a field of flowers.
Camera follows from behind.どんな素材がリファレンスに向いているか
- キャラクターの顔写真(正面、明るい照明、単純な背景のものが参照精度が高い)
- 着せたい衣装・コスチュームの画像(寄りで撮影した服のみの画像)
- 小道具・アイテムの画像(影が少なく背景が白または単色のもの)
- スタイルリファレンス(参照したい絵柄・テイストのサンプル画像)
逆に向いていないのは、背景が複雑で人物と区別しにくい画像、複数の人物が写る集合写真、解像度が低い画像などです。
リファレンス機能の制約まとめ
- 最大7枚まで参照可能
- 最大生成時間:10秒
- i2v(スタートフレーム指定)と同時には使えない。どちらか一方のみ
- 動画編集モードと組み合わせることもできない
Web版での画像参照の実際——@記法の使い方
リファレンス画像を使うとき、「プロンプト内でどう参照すればいいの?」という疑問が必ず出ます。Web版(grok.com/imagine)では、@ キーを入力してアップロード済み画像のドロップダウンから選択するという操作で参照を挿入します。
デスクトップ(grok.com/imagine)での操作手順
- grok.com/imagine で動画モードに切り替え、参照したい画像を最大7枚アップロード
- プロンプト入力欄にカーソルを置き、
@キーを入力 - アップロードした画像のドロップダウンリストが表示される
- 使いたい画像を選択すると「@Image 1」のようなトークンが挿入される
- 複数の画像を参照したい場合は同じ手順を繰り返す
内部的にはこのトークンは @UUID 形式(画像ごとの固有ID)として処理されています。
モバイルアプリでの操作手順
- アプリで「Imagine」をタップ
- プロンプト入力欄から「Video」を選択 → 「Animate Photos」をタップ
- 参照したい画像を最大7枚選択
- プロンプトを入力しながら、参照を挿入したい位置にカーソルを置く
- 参照したい画像のサムネイルをタップ →
@Image 1のトークンが挿入される - アスペクト比・尺・解像度を確認してから送信
<IMAGE_1>はAPI専用の記法:xAIのAPIドキュメントでは<IMAGE_1>、<IMAGE_2>という記法が使われていますが、これはAPI(コード)から呼び出す場合の表記です。Web版のUIでは@からのドロップダウン選択を使います。
プロンプト内での具体的な参照例
シーン指定型(キャラクターに役割を与える):
@Image 1 is walking toward the camera along a quiet forest path.
Warm afternoon sunlight filters through the trees.
Cinematic, slow motion.関係性型(複数キャラクターを使う):
@Image 1 and @Image 2 are sitting together at a café table,
laughing and talking. Close-up shots alternating between them.衣装・小道具指定型:
The character from @Image 1 is wearing the outfit from @Image 2.
They are standing in the rain under a streetlight at night.「思ったキャラが出てこない」問題
「@image1が@image2と遊んでいる」というプロンプトを書いたのに、まったく関係ない人物が出てきた——という経験をしている方は多いはずです。
これはGrok Imagineの現状の挙動として起こりやすく、以下が原因として考えられます。
- プロンプト内の
@image1という記法をAIが必ずしも「アップロード画像の参照」として解釈しない場合がある - 参照画像の内容とプロンプトの文脈が競合すると、プロンプト側が優先されることがある
- 参照画像の人物より、テキストで描写した人物のほうが「引力が強い」ケースがある
次のセクションでこの問題への対策を詳しく解説します。
リファレンス画像が思い通りにならない理由と対策
リファレンス画像機能はまだ発展途上の機能であり、「必ず参照画像の通りになる」という保証はありません。ここでは、再現性を上げるために有効な取り組みをまとめます。
対策1:参照画像の質を上げる
リファレンス画像として機能しやすい画像の特徴:
- 単一の被写体が大きく写っている(背景が単色・白がベスト)
- 顔が正面を向いている(顔認識の精度が上がる)
- 解像度が高く、ぼけていない
- シンプルな服装・アクセサリー(複雑すぎると省略される)
対策2:プロンプトで物理的特徴を補足する
参照画像の内容をプロンプトでも説明することで、AIの「解釈のズレ」を減らせます。
The woman from @image1 — short black hair, red scarf, navy coat —
walks through a snowy park. The camera follows her from behind.「@image1の女性」と書くだけでなく、その人物の特徴を言語でも補うことで、参照画像のない方向へ生成が暴走するリスクが下がります。
対策3:参照画像を分割する
キャラクターと背景・衣装は別々の画像として渡す。例えば「キャラ顔写真(@image1)」+「着せたい服(@image2)」をそれぞれ独立した画像にするほうが、1枚にまとめるより機能しやすいケースがあります。
対策4:英語プロンプトを使う
Grok ImagineはWebインターフェースから日本語でのプロンプトも受け付けますが、より細かいニュアンスを伝えたい場合は英語のほうが精度が安定する傾向にあります。
対策5:複数回生成して「当たり」を拾う
AI生成はランダム性があり、同じプロンプトでも出力がかなり変わります。特にリファレンス画像の反映精度はばらつきが大きいため、3〜5回生成して最も意図に近いものを採用するのが実務的です。
対策6:短い尺で確認してから伸ばす
最初から10秒で生成するのではなく、まず3〜4秒で生成して参照画像が正しく反映されているか確認してから、動画延長で伸ばすアプローチが効率的です。参照が崩れていたら伸ばしても崩れたまま続くので、確認のコストを最初に払うほうが節約になります。
現実的な期待値
率直に言うと、リファレンス画像機能は「確実にそのキャラクターが出る」という機能ではなく、「そのキャラクターが出やすくする」機能です。特に複数のリファレンス画像を同時に使う場合、AIがどの画像のどの要素を優先するかがブラックボックス的になるため、同一キャラクターを安定して出し続けるには試行錯誤が必要です。
他のAI動画生成ツール(例:RunwayのActor機能、KlingのConsistency mode)も同様の課題を抱えており、現状のAIモデル全体の限界とも言えます。
エンドフレームは指定できる?現状と代替手段
「スタートフレームとエンドフレームの両方を指定して、その間を自然につないだ動画を作りたい」という要望は、動画生成ツールを使う多くの人が抱える欲求です。
結論から言うと——
現時点(2026年3月)のGrok Imagineには、エンドフレームを指定する専用の機能は存在しません。
| 機能 | スタートフレーム指定 | エンドフレーム指定 |
|---|---|---|
| i2v(画像→動画) | ✅ 可能 | ❌ 不可 |
| リファレンス画像 | ❌ 固定されない | ❌ 不可 |
| 動画延長 | — | ❌ 不可 |
では、それに近いことを実現するにはどうすればよいか。いくつかの代替アプローチを紹介します。
アプローチ1:i2v + エンドフレームをプロンプトで詳述する
スタートフレームはi2vで固定し、動画の終着点をプロンプトで詳細に記述します。
[Start] The character is standing with arms at their sides, looking down.
[Action] Slowly raises both arms outward and looks up at the sky.
[End] Arms fully extended sideways, face tilted up toward the light.
Camera: static wide shot. Duration: 8 seconds.「Start」「Action」「End」のような構造を明示することで、AIが終着状態を意識して生成しやすくなります。完全な保証はありませんが、指定なしよりはコントロールしやすくなります。
アプローチ2:動画延長を重ねていく
i2vで最初のクリップを生成 → プロンプトで「次の状態へ」と延長 → これを繰り返してエンドフレームに近づける、という方法です。
延長プロンプト例:
Continue the same camera movement. The character continues to slowly
raise their arms, almost reaching the fully extended position.
Maintain the same lighting and camera angle.繰り返し延長できる回数に制限はありませんが、延長ごとに見た目の一貫性が若干下がっていくことがあります。
アプローチ3:リファレンス画像で「目標状態」を示す
- @image1:スタートに近いシーン(キャラクターのポーズA)
- @image2:ゴールに近いシーン(キャラクターのポーズB)
The character in @image1 transitions from their initial pose
to the pose in @image2 over the course of the video.
Smooth, natural movement. 8 seconds.「移行する」という動詞でつなぐと、AIがAからBへの動きとして解釈しやすくなります。ただし参照画像の反映率は前述のとおりばらつきがあるため、何度か試す必要があります。
エンドフレーム機能の今後
機能として望む声は非常に多く、類似ツールでは RunwayのGen-4(First/Last Frame機能)、Kling 3.0(Start/End Frame機能)などがすでに対応しています。Grok Imagineも今後のアップデートで対応する可能性は十分あります。
思い通りの動画を作るための実践テクニック集
公式ドキュメントと使用体験から導き出した、動画クオリティを上げるテクニックをまとめます。
カメラワークをプロンプトに明示する
動画生成で「なんとなくボヤッとした動き」になる主因は、カメラの挙動を指定していないことです。以下のような表現をプロンプトに盛り込むと、意図通りになりやすくなります。
ズーム系
slow zoom in on the character's face— 顔へのゆっくりズームcinematic zoom-out revealing the full scene— 全景が見えてくるズームアウトdolly zoom effect— 被写体は同サイズのままで背景が変わるトリックショット
パン・移動系
camera pans slowly from left to right— 左から右へのパンtracking shot follows the character— キャラクターを追うトラッキングover the shoulder shot— 肩越しアングルbird's eye view, drone shot— 上空からのドローン視点
固定系
static camera, no movement— カメラ固定。動かしたくないときに明示するlocked down shot— 三脚で固定したような安定した映像
尺の戦略:短く作って延ばす
最初から15秒の動画を作ろうとしてもコントロールが難しく、途中でキャラクターの見た目が崩れたり、予期しない動きが入ったりします。推奨フローは:
- 3〜5秒で生成(テスト用)
- 意図通りのシーンが生成できたら、動画延長で8〜10秒に
- さらに続きが必要ならもう一度延長
このステップアプローチで、最終的に20〜25秒の動画を作ることも可能です。
解像度の使い分け
| 解像度 | 使いどころ | 備考 |
|---|---|---|
| 480p | プロトタイプ・確認用 | 生成が速い。デフォルト設定 |
| 720p | 本番出力・SNS投稿 | SuperGrokプランで利用可能。HD品質 |
試行錯誤フェーズは480pで速く回して、GOサインが出たら720pで本番生成するのが費用対効果が高いです。
アスペクト比は最初から決める
| アスペクト比 | 用途 |
|---|---|
| 16:9 | YouTube・横長コンテンツ(デフォルト) |
| 9:16 | TikTok・Reels・ストーリーズ |
| 1:1 | Instagramフィード・X(Twitter) |
| 3:2 / 2:3 | 写真的なポートレート・プリント |
| 4:3 | プレゼン・レトロ系 |
i2vの場合は入力画像のアスペクト比がデフォルトで引き継がれます。出力比率を変えたいときはプロンプトか設定で明示的に上書きします(注:画像が引き伸ばされます)。
照明・雰囲気の記述で動画の「色気」が変わる
技術的な指示だけでなく、照明や雰囲気をプロンプトに加えることで動画のビジュアルクオリティが大きく向上します。
warm golden hour lighting, soft shadows, shallow depth of field
cinematic color grading, cool blue tones, high contrast
harsh studio lighting, clean background, product photography styleプロンプトは英語のほうが精度が安定しやすい
細かいニュアンス指定は英語が有利です。ただし日本語でも基本的な生成は問題なく動きます。複雑な指示のときは英語、シンプルなシーン指定なら日本語でも依存しない、というスタンスで使うと使いやすいです。
動画延長機能の使い方
動画延長の仕組み
動画延長は、既存の動画の「ラストフレームから続き」を生成して1本に結合する機能です。
- 入力動画の長さ:2〜15秒
- 延長できる長さ:2〜10秒(デフォルト6秒)
- 出力:元の動画+延長部分を結合した1本
- アスペクト比・解像度:元の動画に自動で合わせられる(最大720p)
注意:延長の数値は「延長する分だけの長さ」です。元が10秒の動画に6秒の延長を指定すると、返ってくる動画は合計16秒になります。
Web版での使い方
- Grok Imagineで生成済みの動画を表示
- 動画の下部または操作メニューから「動画を延長する」を選択
- 延長後の動きをプロンプトで指示
- 必要に応じて延長時間を設定して生成
延長プロンプトのコツ
カメラワークの継続性を指定する:
Continue the same camera movement.
The character walks forward until they reach the doorstep.
Maintain the same lighting and atmosphere.シーン転換させる場合:
Cut to a close-up of the character's face.
They pause, look directly into the camera.
Same warm lighting.背景・環境動画の単純延長:
Continue the same gentle wave motion. Static camera.ゴーストアーティファクト問題——何が起きているのか
3月のアップデート後から、動画延長時に画面にゴースト(半透明の人物や残像)が映り込むという報告がユーザーの間で増えています。
ゴーストとはどういう現象か
動画の一部(特に延長された部分)に、元のキャラクターや前のフレームの残像が薄く重なって見える現象です。ホラー映画のような半透明の人物が一瞬出たり、フレームの端に前のシーンの残影が残ったりします。
いつから・なぜ発生するのか
3月のマルチ画像対応アップデート後から報告が増えているため、このアップデートに伴うモデルまたは処理パイプラインの変化が原因に絡んでいる可能性があります。ただし、xAIから公式な原因説明や修正リリースは2026年3月31日時点ではアナウンスされていません。
発生しやすい条件として報告されているもの:
- 速いモーションのある動画を延長するとき
- 明暗差が大きいシーンの延長
- 複数回延長を繰り返したとき(2回目以降から崩れやすい)
現状でできる回避策
① 入力動画のモーションを穏やかにする
激しく動くシーンより、ゆっくりした動きやカメラが固定された動画のほうがゴーストが出にくい傾向があります。
② 延長時間を短くする
デフォルト(6秒)より短い2〜3秒に設定すると、アーティファクトが抑えられる場合があります。
③ プロンプトでカメラを固定する
static camera, no movement をプロンプトに加えることで、カメラの動きに起因するアーティファクトが軽減されることがあります。
④ ループ延長を控える
1本の動画を繰り返し延長していくと崩れやすくなります。必要な長さのベースクリップを最初から作り直したほうが早いこともあります。
⑤ 修正を待つ(あるいは別ツールで補完する)
xAIは積極的にモデルの改善を続けており、このような品質問題は短期間で修正されるケースが多いです。急ぎで対処が必要な場合は、CapCut・DaVinci Resolve などの動画编集ソフトで問題のあるフレームを手動でカットするのも実際的な対処です。
プラン比較:LiteとSuperGrokどちらが必要か
Grok Imagineの画像・動画生成機能を本格的に使うには有料プランへの加入が必要です。無料プランでは生成回数がほとんどなく、試用レベルです。(出典:grok.com/plans、2026年3月31日調査)
プラン一覧
| プラン | 月額 | 画像・動画生成 | 動画品質 | チャット |
|---|---|---|---|---|
| 無料 | $0 | ほぼ使えない | 制限あり | 標準 |
| SuperGrok Lite | $10 USD | 試用レベルの枠 | 制限あり | 会話長さ2倍 |
| SuperGrok | $30 USD | 無料比20倍 | HD 720p | 会話長さ5倍 |
SuperGrok Liteで何ができるか
Liteは月10ドルの入門プランです。Imagineを「少し試してみたい」用途には向いていますが、本記事で解説するリファレンス画像や動画延長を繰り返し使うには枠が足りなくなる可能性があります。
含まれる主な機能:
- AIチャット:会話の長さが無料の2倍
- Expertモードで1AIエージェント利用
- AI画像・動画の生成(試用枠)
- 通常速度の利用枠拡大
SuperGrokで何ができるか
月30ドルの上位プランです。ドキュメントには「3日間無料トライアル」が記載されています(2026年3月時点)。
含まれる主な機能:
- 画像・動画の生成数が無料比20倍
- 動画をHD 720pで生成可能
- Expertモードで4AIエージェントが連携
- ファイルアップロード数が増え、コンテキスト理解が向上
- 超高速返信
裏技:X Premium Plusに加入するとSuperGrokが付いてくる
実はSuperGrokを使うなら、X Premium Plusに加入する方が得になるケースがあります。
X Premium PlusにはSuperGrok(月額$30相当)が標準で含まれており、さらにXの全機能(広告ゼロ、X Pro、Radarアドバンストサーチなど)も使えます。
そして現時点では新規加入から2ヶ月間、50%割引のキャンペーンが実施されています。
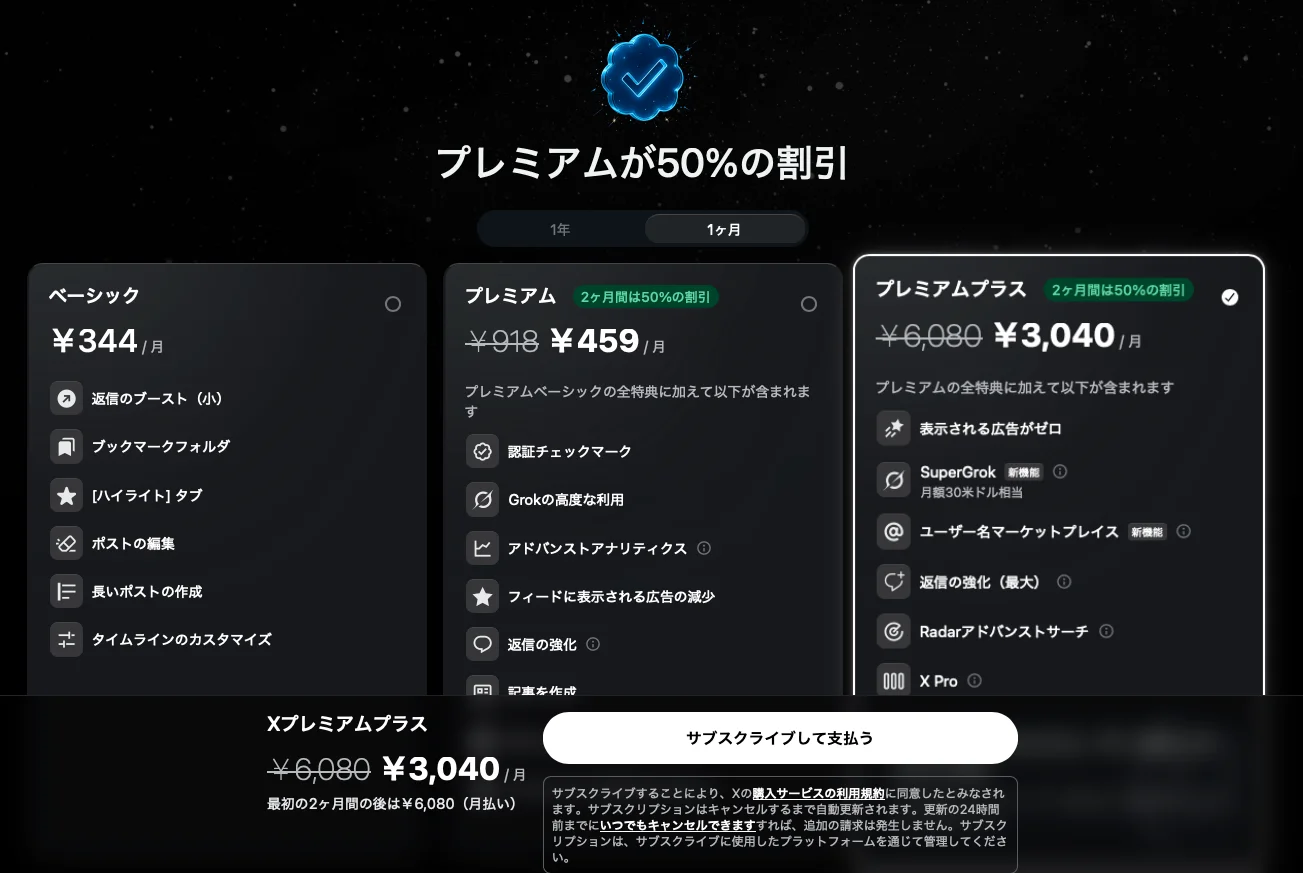
| プラン | 通常価格 | 2ヶ月間の割引価格 |
|---|---|---|
| X Premium Plus | ¥6,080/月 | ¥3,040/月 |
| SuperGrok単体 | ¥4,500/月相当($30) | 割引なし |
割引期間中はX Premium Plus(¥3,040/月)がSuperGrok単体(約¥4,500/月)より安くなります。しかもXの広告ゼロや各種機能まで付いてくるため、最初の2ヶ月はX Premium Plusから始めるのがお得です。3ヶ月目以降は通常料金(¥6,080/月)に戻るので、そのタイミングでSuperGrok単体(¥4,500/月相当)に切り替えるかどうかを判断するとよいでしょう。
登録は x.com/i/premium_sign_up から。
⚠️ 注記:上記のキャンペーン価格・割引条件は2026年4月2日時点の情報です。期間限定のキャンペーンのため、内容が変更・終了している場合があります。最新情報は x.com/i/premium_sign_up でご確認ください。
どちらを選ぶか
クリエイターや動画制作を頻繁に行う方にはSuperGrok(月$30相当)が実質一択です。リファレンス画像や動画延長は試行錯誤を繰り返す機能なので、生成枠が少ないとすぐ使い切ってしまいます。「とにかく一度試してみたい」という方はSuperGrok Lite(月$10)から始めて様子を見るのが無難です。なお、前述の通り加入直後の2ヶ月間はX Premium Plusの割引キャンペーンがお得なため、まずそちらを検討してみてください。
まとめ
| 疑問 | 答え |
|---|---|
| 複数画像でキャラクター参照できる? | ✅ リファレンス画像機能(最大7枚)で対応。スタートフレームは固定されない |
参照記法は<IMAGE_1>か@image1か? | APIは<IMAGE_1>が公式。Web版は@image1の報告あり。どちらも試してみるのが現実的 |
| エンドフレームは指定できる? | ❌ 専用機能はなし。プロンプト詳述・動画延長の組み合わせで近似可能 |
| 参照画像通りにキャラが出ない | 参照画像の質向上・プロンプトで特徴を補足・複数回生成で対応 |
| 動画延長のゴーストアーティファクトは? | ❌ 3月アップデート後から報告増。短い延長尺・穏やかな入力動画で緩和可能 |
| 無料で使える? | ❌ SuperGrok Lite ($10/月)以上が必要。本格的にはSuperGrok ($30/月)推奨 |
Grok Imagineは機能の追加ペースが速く、本記事で「現時点では未対応」と書いたエンドフレームについても、競合他社の実装状況を見ると近日中に追加される可能性は十分あります。公式アカウント @grok と @imagine のポストをチェックしておくと、アップデートをいち早くキャッチできます。
調査・出典
- xAI公式 @grok「Grok Imagine multi-image to video…」— https://x.com/grok/status/2036533528847065108(2026年3月25日)
- xAI公式 @imagine — https://x.com/imagine/status/2037602980917280952(2026年3月28日)
- xAI公式ドキュメント – Video Generation — https://docs.x.ai/developers/model-capabilities/video/generation(2026年3月31日調査)
- grok.com/plans — https://grok.com/plans(2026年3月31日調査)
- Artificial Analysis Text-to-Video Leaderboard — https://artificialanalysis.ai/video/leaderboard/text-to-video(2026年3月31日調査)